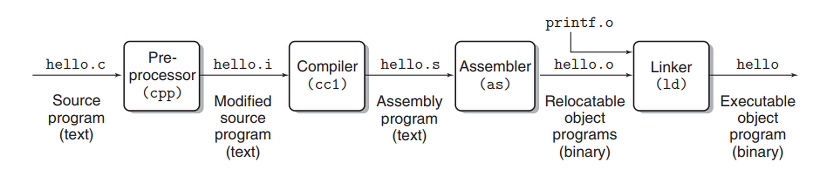
C/C++를 리눅스환경에서 컴파일하는데에는 gcc(Gnu C Compiler)와 g++(Gnu C++ compiler)명령이 있다. hello.c 파일을 안에두고 gcc -o hello hello.c 명령을 수행하면 hello.c c언어 소스파일을 가지고 hello라는 실행가능한 목적파일(executable object file, 이하 실행파일)이 생성된다. --output 스위치를 생략하여 더욱 간략하게 gcc *.c 를 해도되는데 이때는 a.out 실행파일이 생성된다.(그래서 흔히 컴파일결과물을 가지고 a.out이라고 표현한다) 하나의 명령만으로 실행파일을 만들어내니 간단한 과정이라 생각할 수 있지만, gcc는 그 뒤에서 아래와같이 다양한 과정을 통해 실행파일을 만들어낸다. gcc가 모든 컴파일을 직접 수행하는것은 아니고, 대신 다른 프로그램과 함께하여 컴파일링을 주도하기 떄문에 이런 특성을 표현하기 위하여 gcc 'compiler driver'라는 표현을 사용한다.
gcc compile 과정
컴파일 과정은 크게 '전처리기, 컴파일러, 어셈블러, 링커(Pre-processor, Compiler, Assembler, Linker)'에 의한 4개의 단계로 나눌 수 있다. 아래에 그 과정에 대하여 정리하였다. gcc 사용자가 유심히 보아야할 부분은 목적파일을 만들어내는 어셈블러부분과(gcc -c *.c) 목적파일들을 엮어서 하나의 실행파일로 만들어주는 링커부분(gcc -o *.o)이다. 참고로 gcc를 사용할 때 -v 스위치를 사용하면 gcc 뒤에서 어떤 프로그램이 어떻게 수행되는지 더욱 자세히 확인할 수 있다.
1. 전처리 단계 (cpp 프로그램 사용 -- C PreProcessor)
hello.c 소스파일에서 # 문자로 시작되는 지시자들에 대한 처리를 한다. 예를 들어서 #include "header.h"라는 코드가 있는경우 시스템에서 header.h 파일을 읽어와 해당 소스파일에 그대로 삽입시킨다. 전처리가 완료된 소스파일은 파일이름뒤에 .i 가 붙어서 저장된다.
2. 컴파일 단계 (cc1 프로그램 사용, c++는 cc1plus, obj-c는 cc1obj 사용)
전처리 단계에서 생성된 hello.i 파일을 읽어와 어셈블리 언어(pushq, addl등의 명령으로 이루어진 기계어)로 변환하여 .s 파일을 생성한다. c가 아닌 다른 언어라도 컴파일단계에서 기계어로 변환되기 때문에, 다음단계인 어셈블리 단계에서는 사용자가 어떤 고수준 언어를 사용했는지 걱정할 필요가 없다.
3. 어셈블리 단계 (as 프로그램 사용)
hello.s의 내용을 더욱 쪼개서 instruction 단위로 만들고 이것을 한데모아 재배치가능한 목적프로그램(relocatable object program) 의 단위로 묶어 .o 파일을 만든다. 각각의 object 파일은 번역단위를 바탕으로 작성이 되는데, 번역단위란, 컴파일를 통해 하나의 목적파일을 만드는 바탕이 되는 소스코드를 말하며, 전처리기를 거친(# 지시자등이 모두 처리된) 하나의 c 파일이라고 생각할 수 있다. 또한 재배치 가능하다는 의미는 링커를 통해 다른 목적파일들과 결합이 가능하다는것을 의미한다. 이러한 특성으로, 프로그램 소스코드의 일부가 변경되었을 때 전체 소스에 대한 컴파일을 새로 수행하는 것 대신, 해당 목적파일만 생성하고 교체하면 되기때문에 컴파일의 효율성이 높아진다. 이 단계부터는 사람이 읽을 수 없는 내용으로 파일이 만들어진다. (binary 파일)
4. 링킹 단계 (ld 프로그램 사용)
많은 프로그램들은 외부의 라이브러리를 참조한다. 대표적으로 화면에 글씨를 출력해주는 printf 함수가 있으며 이는 표준 C 라이브러리에 포함되어 printf.o 목적파일형태로 대부분의 컴파일러와 함께 제공된다. hello.o 파일과 printf.o 파일을 결합해야만 프로그램이 정상작동하게 되는데, 이러한 결합은 링커 프로그램을 통해 이루어진다. (.so, .a 로 표현되는 동적 정적 라이브러리에 관해서는 다음에 더 자세히 다루도록 한다) 이 단계가 완료되면 그 결과로 실행파일이 생성되어 사용자에게 배포될 수 있다.